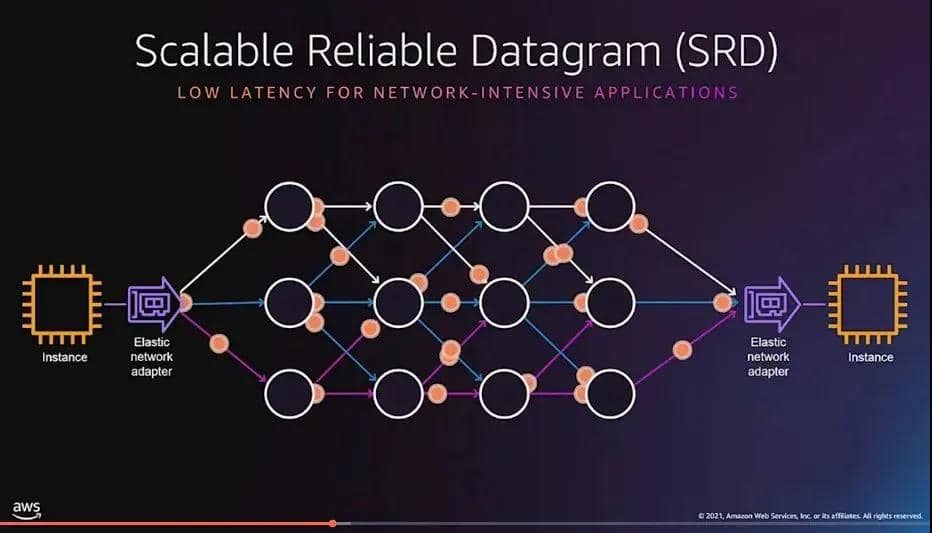
AWS 2022 re:invent 大会上已经把SRD应用在自己的云服务中,来替换掉笨重的TCP协议,达到提高性能,减少延迟,增加稳定性的目的。
SRD是AWS技术团队提出的一种网络协议,原始论文在:https://ieeexplore.ieee.org/document/9167399 ,我在这里利用在线翻译软件对该论文做了中文翻译以便大家更好理解。
摘要
Amazon Web Services (AWS) 重新审视了网络,以提供超级计算应用程序所需的持续低延迟,同时保持公共云的优势:可扩展性、弹性按需容量、成本效益以及快速采用更新的 CPU 和 GPU . 我们构建了一个新的网络传输协议,可扩展的可靠数据报 (SRD),旨在利用现代商品多租户数据中心网络(具有大量网络路径),同时克服它们的局限性(负载不平衡和不相关流冲突时不一致的延迟)。 SRD 不是保留数据包顺序,而是通过尽可能多的网络路径发送数据包,同时避免过载路径。 为了最大限度地减少抖动并确保对网络拥塞波动做出最快的响应,SRD 在 AWS 定制的 Nitro 网卡中实现。 SRD 由 EC2 主机上的 HPC/ML 框架通过 AWS 弹性结构适配器EFA内核旁路接口使用。
发表于: IEEE Micro ( 体积: 40 , 问题: 6 , 11 月 1 日至 12 月 2020 ) 页数: 67 – 73 出版日期: 2020 年 8 月 14 日 ISSN 信息: INSPEC 登录号: 20074360 DOI: 10.1109/MM.2020.3016891 出版商: IEEE
云计算的主要优势之一是能够根据需要即时供应和取消供应资源。 这与传统的超级计算截然不同,在传统超级计算中,物理超级计算机是定制的(需要数月或数年)并且由于成本高且容量有限而不易访问。 使用定制系统进行超级计算的主要原因之一是构建高性能网络并在应用程序之间共享它的挑战。 在云计算的背景下,使用 InfiniBand 等专用硬件或专用于 HPC 工作负载的商品硬件都非常昂贵、难以扩展且难以快速发展。
Amazon Web Services (AWS) 选择使用现有的 AWS 网络(最低 100 Gbps)为客户提供负担得起的超级计算,并添加了一个新的 HPC 优化网络接口作为 AWS Nitro 卡提供的网络功能的扩展。
正如预期的那样,在共享网络上运行 HPC 流量会带来一系列挑战。 AWS 使用商用以太网交换机构建具有等价多路径 (ECMP) 路由的高基数折叠 Clos 拓扑。 ECMP 通常用于使用流哈希跨可用路径静态条带化流。 这种流到路径的静态映射有利于保持 TCP 的每个流顺序,但它不考虑当前网络利用率或流率。 散列冲突会在某些链路上产生“热点”,从而导致路径间的负载分布不均匀、数据包丢失、吞吐量下降和高尾延迟(正如广泛研究的那样,例如,在 Al-Fares 等人的文章中 , 1 Ghorbani 等人 , 2 Handley 等人 , 3 Hopps 等人 , 4 和 Vanini 等人 )。 5 即使在过度配置的网络中,大流量也可能会影响不相关的应用程序。
数据包延迟和数据包丢失会干扰 HPC/ML 应用程序的低延迟要求,从而导致扩展效率降低。 延迟异常值对这些应用程序有深远的影响,因为它们通常遵循批量同步并行编程模型,计算时代之后是整个集群的批量同步。 单个异常值会使整个集群等待,由于 Amdahl 定律限制了可扩展性。
为什么不是 TCP
TCP 是 IP 网络中可靠数据传输的主要方式,它自 Internet 诞生以来一直很好地服务于 Internet,并且仍然是大多数通信的最佳协议。 但是,它不适合对延迟敏感的处理。 对于数据中心中的 TCP,虽然最佳情况下的往返延迟可能高达 25 微秒,但拥塞(或链路故障)下的延迟异常值可能介于 50 毫秒和几秒之间,即使替代的非拥塞网络路径是可用的。 这些异常值的主要原因之一是重新传输丢失的 TCP 数据包:TCP 实现被迫保持较高的重新传输超时,以解决操作系统延迟问题。
为什么不 RoCE
InfiniBand 是一种流行的用于高性能计算的高吞吐量低延迟互连,它支持内核旁路和传输卸载。 RDMA over Converged Ethernet (RoCE),也称为 InfiniBand over Ethernet,允许在以太网上运行 InfiniBand 传输,理论上可以在 AWS 数据中心提供 TCP 的替代方案。 我们考虑了 RoCEv2 支持,并且弹性结构适配器 (EFA) 主机接口与 InfiniBand/RoCE 接口非常相似。 但是,我们发现 InfiniBand 传输不适合 AWS 的可扩展性要求。 原因之一是 RoCE [v2] 需要优先级流量控制 (PFC),这在大规模网络上是不可行的,因为它会造成线头阻塞、拥塞扩散和偶尔出现的死锁。 的文章中描述了大规模 PFC 问题的一种解决方案, Guo [6] 但它明确依赖于比 AWS 数据中心小得多的数据中心规模。 此外,即使使用 PFC,RoCE 仍然会在拥塞下遭受 ECMP 冲突,类似于 TCP,以及次优的拥塞控制。 [7]
我们的方法
由于 TCP 和其他传输协议都无法提供我们需要的性能级别,因此在我们使用的网络中,我们选择设计自己的网络传输。 可扩展可靠数据报 (SRD) 针对超大规模数据中心进行了优化:它提供跨多条路径的负载平衡以及从丢包或链路故障中快速恢复。 它利用商用以太网交换机上的标准 ECMP 功能并解决其局限性:发送方通过操纵数据包封装来控制 ECMP 路径选择。 SRD 采用专门的拥塞控制算法,通过将队列保持在最低限度,有助于进一步减少数据包丢失的机会并最大限度地减少重传次数。
我们对协议保证做了一个有点不寻常的选择:SRD 提供可靠但无序的交付,并将顺序恢复留给它上面的层。 我们发现严格的按顺序交付通常是不必要的,强制执行它只会造成队头阻塞、增加延迟并减少带宽。 例如,如果使用相同的消息标签,则消息传递接口 (MPI) 标记的消息只需要按顺序传递。 因此,当网络中的并行性导致数据包无序到达时,我们将消息顺序恢复留给上层,因为它对所需的排序语义有更好的理解。
我们选择在 AWS Nitro 卡中实施 SRD 可靠性层。 我们的目标是让 SRD 尽可能靠近物理网络层,并避免主机操作系统和管理程序注入的性能噪声。 这允许快速适应网络行为:快速重传和迅速减速以响应队列建立。
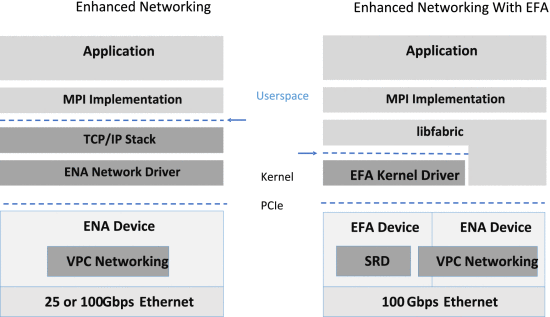
SRD 作为 EFA PCIe 设备暴露给主机。 EFA 是 Amazon EC2 实例(即虚拟和裸机服务器)的网络接口,使客户能够在 AWS 上大规模运行紧密耦合的应用程序。 特别是,EFA 支持运行 HPC 应用程序和 ML 分布式训练,目前在多个 MPI 实现中受支持:OpenMPI、Intel MPI 和 MVAPICH,以及 NVIDIA Collective Communications Library。 所示 如图 1 ,EFA 提供了一个“用户空间驱动程序”,它利用操作系统 (OS) 绕过硬件接口来增强实例间通信的性能(减少延迟、抖动、避免 OS 系统调用和减少内存副本) ),这是扩展这些应用程序的关键。
可扩展的可靠数据报设计
多路径负载平衡
为了减少数据包丢失的机会,流量应该在可用路径上均匀分布。 SRD 发送方需要在多个路径上喷射数据包,即使是单个应用程序流,尤其是大流量,以最大限度地减少热点的机会,并检测次优路径。 我们将 SRD 设计为与未启用多路径的遗留流量共享网络,因此仅随机喷射流量是不够的。 为了最大限度地减少繁重的传统流量的影响,SRD 使用为每条路径收集的往返时间 (RTT) 信息来避免过载路径。
在规模上,偶尔的硬件故障是不可避免的; 为了允许从网络链路故障中快速恢复,SRD 能够在用于原始传输的路径变得不可用的情况下重新路由重传的数据包,而无需等待网络范围的路由更新收敛,这需要 2-3 个数量级的时间。 此路由更改由 SRD 完成,无需代价高昂的重新建立连接。
乱序交付
平衡多条可用路径之间的流量有助于减少排队延迟并防止数据包丢失,但是,它不可避免地会导致大型网络中数据包无序到达。 众所周知,恢复网卡中的数据包排序非常昂贵,网卡通常资源有限(内存带宽、重新排序缓冲区容量或开放排序上下文的数量)。
我们考虑让 Nitro 网卡按顺序发送接收消息,类似于 TCP 或无限带宽可靠连接 (RC) 等常见的可靠传输。 但是,这会限制可扩展性或在出现丢包时增加平均延迟。 如果我们推迟向主机软件交付无序数据包,我们将需要一个大的中间缓冲区,并且我们将大大增加平均延迟,因为许多数据包被延迟,直到丢失的数据包被重新发送。 大多数或所有这些数据包很可能与丢失的数据包无关,因此这种延迟是不必要的。 丢弃无序数据包“解决”了缓冲问题,但没有解决延迟问题,并增加了网络带宽消耗。 因此,我们决定将数据包传送到主机,即使它们可能是无序的。
应用程序处理无序数据包对于字节流协议(例如 TCP)是站不住脚的,其中消息边界对传输层是不透明的,但在使用基于消息的语义时很容易。 每流排序或其他类型的依赖跟踪由 SRD 之上的消息传递层完成; 消息层排序信息与数据包一起传输到另一端,对 SRD 不透明。
拥塞控制
多路径喷射减少了网络中中间交换机的负载,但它本身并不能缓解 incast 拥塞问题。 Incast 是一种流量模式,其中许多流汇聚在交换机的同一接口上,耗尽该接口的缓冲区空间,导致数据包丢失。 这在多对一通信模式中连接到接收器的最后一跳交换机中很常见,但也可能发生在其他层。 [2]
喷射实际上会使 incast 问题变得更糟,因为来自同一发送方的微突发,即使最初受到发送方链路带宽的限制,也可能同时到达不同的路径。 因此,多路径传输的拥塞控制将所有路径上的聚合排队保持在最低限度是至关重要的。
SRD 拥塞控制的目标是以最少的传输字节获得公平的带宽份额,防止队列建立和数据包丢失(而不是依赖它们进行拥塞检测)。 SRD 拥塞控制有点类似于 BBR, [8] 具有额外的数据中心多路径考虑因素。 它基于每个连接的动态速率限制,并结合了飞行限制。 发送方根据传入确认数据包的时间指示的速率估计调整其每个连接的传输速率,同时考虑最近的传输速率和 RTT 变化。 如果 RTT 在大多数路径上上升,或者如果估计速率变得低于传输速率,则检测到拥塞。 这种方法允许检测影响所有路径的连接范围的拥塞,例如,在 incast 的情况下。 单独路径上的拥塞通过重新路由独立处理。
用户界面:EFA
Nitro 卡上的 SRD 传输通过 EFA 向 AWS 客户公开。 EFA 接口类似于 InfiniBand 动词。 [9] 然而,其 SRD 语义与标准 InfiniBand 传输类型截然不同。 EFA 用户空间软件有两种形式:基本的“用户空间驱动程序”软件公开可靠的无序交付,由 Nitro 卡 EFA 硬件设备本地提供,而 libfabric [10] “提供程序”在其之上分层实现数据包重新排序作为消息分段和 MPI 标签匹配支持的一部分。
EFA 作为弹性网络适配器的扩展
Nitro 卡是一系列卡,可卸载和加速 AWS EC2 服务器上的网络、存储、安全和虚拟化功能。 特别是,用于 VPC 的 Nitro Card 包括弹性网络适配器 (ENA) PCIe 控制器,它向主机提供经典网络设备,同时还实现了 AWS VPC 的数据平面。 增强网络使用 PCIe 单根 I/O 虚拟化 (SR-IOV) 来提供高性能网络功能,而无需管理程序参与; 它将专用 PCIe 设备暴露给在 AWS 主机上运行的 EC2 实例,与传统的半虚拟化网络接口相比,可实现更高的 I/O 性能、更低的延迟和更低的 CPU 使用率。 EFA 是 Nitro VPC 卡在适用于 HPC 和 ML 的 AWS 高性能服务器上提供的附加可选服务。
EFA SRD 传输类型
与 InfiniBand 动词一样,所有 EFA 数据通信都是通过队列对 (QP) 完成的,队列对是可寻址的通信端点,包含一个发送队列和一个接收队列,用于提交请求以异步发送和接收消息,直接从/到用户空间. QP 是昂贵的资源,传统上需要大量的 QP 才能在大型集群(其中通常在每台服务器上运行大量进程)中建立所有进程连接。 如 https://github.com/amzn/amzn-drivers/blob/master/kernel/linux/efa/SRD.txt 中所述,EFA SRD 传输可以显着节省所需数量的 QP 。 [11] EFA SRD 语义类似于 InfiniBand 可靠数据报 (RD) 模型,但消除了 RD 限制(由处理从不同发送者到同一目标 QP 的交错分段消息的难以维持的复杂性引起,同时提供按顺序交付)。 与 RD 不同,SRD QP 乱序传送数据并限制消息大小以避免分段。 这允许在不创建队头阻塞的情况下支持多个未完成的消息,以便可以在不相互干扰的情况下多路复用单独的应用程序流。
乱序数据包处理挑战
EFA SRD QP 语义为 EFA 上层处理引入了一个不熟悉的排序要求,我们称之为“消息层”,通常由 HPC 应用程序用来抽象网络细节。 与成熟的传输实现(如 TCP)相比,这个新功能是轻量级的,因为可靠性层被卸载了。
理想情况下,由消息层完成的缓冲区管理和流量控制应该与应用程序紧密耦合,这是可行的,因为我们的主要重点是类似 HPC 的应用程序,它已经支持并且实际上更喜欢具有管理用户缓冲区能力的用户空间网络.
对于消息语义,如果应用程序消息传递层希望将数据接收到虚拟连续缓冲区而不是收集列表中,那么对于大型传输,消息段的无序到达可能需要数据复制。 这并不比 TCP 差,TCP 需要从内核缓冲区复制到用户缓冲区。 使用 RDMA 功能(超出本文范围)可以在 EFA 中避免此副本。
SRD 性能评估
我们在同一组服务器上将 EFA SRD 性能与 AWS 云上的 TCP(使用默认配置)进行了比较。 我们不分析操作系统内核旁路引起的差异,因为 a) 它对 EFA 的影响与充分研究的 InfiniBand 案例没有本质区别,并且 b) 与拥塞下的传输行为差异相比,它是次要的。
MPI 实施是另一个对 HPC 应用程序性能具有深远影响的因素,特别是对于 EFA 早期版本上的 MPI,如 Chakraborty 等人 的文章所示。 [12] 由于我们的目标是评估传输协议,而 MPI 实现超出了本文的范围,因此我们仅使用 OpenMPI 中的基本 MPI 原语(包括重新排序逻辑),或绕过 MPI 层的微基准测试。
Incast FCT 和公平性
我们评估了从 4 个服务器发送的 48 个独立流,每个服务器运行 12 个进程,到单个目标服务器,在最后一个网络跃点处造成瓶颈。 我们测量 SRD 和 TCP 的流完成时间 (FCT),并将其与最佳 FCT 进行比较,即在 100% 使用瓶颈链路的情况下的理想 FCT 在流之间平均分配。
“Bursty”Incast FCT
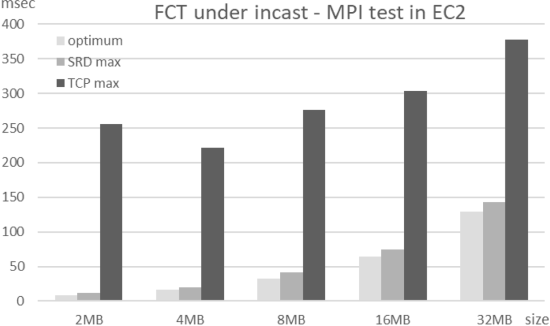
我们在 EFA/SRD 或 TCP 上运行了 MPI 带宽基准测试,此时发送方使用屏障在大约相同的时间开始每次传输 。 图 2 显示了不同传输大小的理想和最大 FCT。 SRD FCT 接近最优,抖动非常低,而 TCP FCT 噪声很大,最大时间比理想值高 3-20 倍。
{kind=link}
{kind=link}
图 3 显示了 2 MB 传输的 FCT 的 CDF。 超过 50 毫秒的 TCP 尾部延迟反映了重传,因为最小重传超时为 50 毫秒。 即使仅查看低于 50 毫秒的样本(即,当延迟不是由超时引起时),大量样本也比理想值高 3 倍。
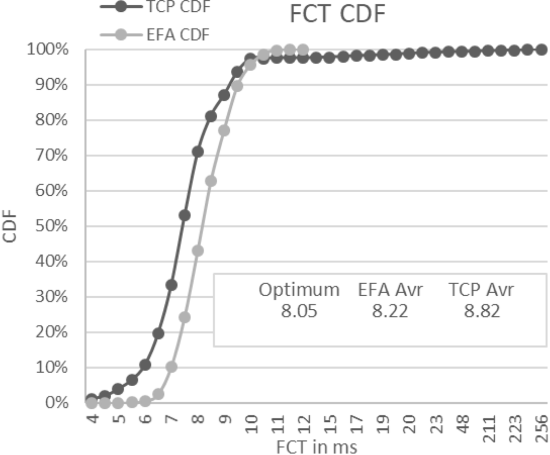
图 3 FCT 的 CDF 用于 2 MB 传输,突发 48 流 incast。
{kind=link}
持续拥塞下的流量吞吐量
为了理解 TCP 的高 FCT 方差(即使由于超时而忽略长尾),我们检查了 incast 下的单个流吞吐量。 我们使用绕过 MPI 的低级基准测试来测量连续发送数据时的吞吐量。 我们每秒对每个流的吞吐量进行采样。 在 100 Gb/s 的组合速率下,每个流的预期公平份额约为 2 Gb/s。
图 4 显示了两个代表性发件人各自的 TCP 和 SRD 吞吐量。 SRD 流的吞吐量对于所有流都是一致的并且接近理想状态,而每个流的 TCP 吞吐量都在剧烈波动,并且一些流的平均吞吐量比预期低得多,这解释了 FCT 抖动。
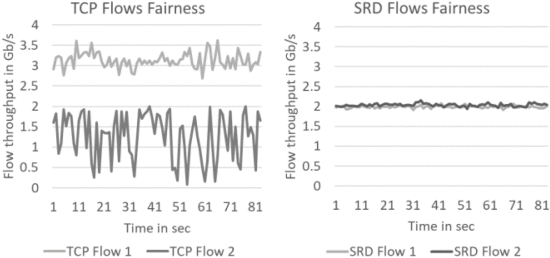
图 4 吞吐量每秒采样,48 路 incast,代表性流量。
{kind=link}
多路径负载平衡
我们还评估了一个要求不高的案例,没有相关负载。 所示 如图 5 ,我们在全平分网络中运行了从位于同一机架中的 8 台服务器到位于另一个机架中的 8 台服务器的多个流。 每台机器运行 16 个 MPI 等级(进程),所有这些都在不同的流上向/从同一台远程机器发送或接收数据。 TOR 交换机上行链路使用率为 50%,预计下行链路不会拥塞,因为只有一个发送方向任何接收方发送数据。
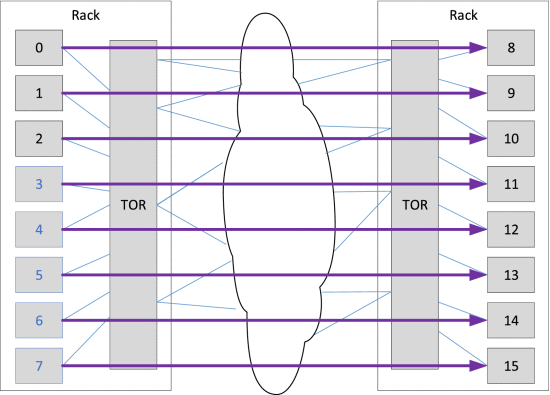
{kind=link}
图 6 显示了 TCP 和 EFA 的 8 个发送器之一的所有流的 FCT(其他发送器看起来相似)。 即使采用理想的负载平衡,根本不会出现拥塞,但由于交换机间链路的 ECMP 平衡不均匀,TCP 显然会出现拥塞甚至丢包。 TCP 中值延迟变化很大,平均值比预期高 50%,而尾延迟比预期高 1-2 个数量级。 中值 SRD FCT 仅比理想值高 15%,最大 SRD FCT 低于平均 TCP FCT。
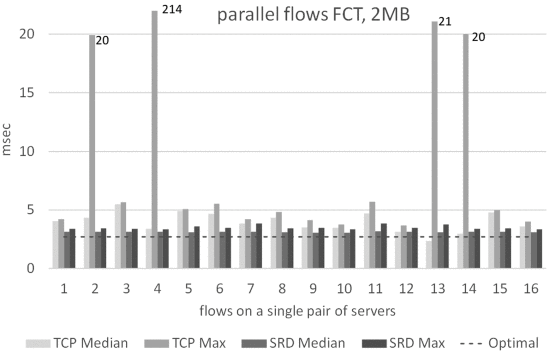
{kind=link}
结论
EFA 允许 HPC/ML 应用程序在 AWS 公有云上大规模运行。 它提供始终如一的低延迟,尾部延迟数量级低于 TCP。 这是通过 SRD 提供的新颖网络传输语义,结合网络接口卡和不同主机软件层之间的非正统功能划分来实现的。 通过在 Nitro 卡上运行 SRD 多路径负载平衡和拥塞控制,我们既减少了网络中丢包的几率,又能更快地从丢包中恢复。
致谢
作者要感谢 E. Izenberg、Z. Machulsky、S. Bshara、M. Wilson、P. DeSantis、A. Judge、T. Scholl、R. Galliher、M. Olson、B. Barrett 和 A. Liguori感谢他们帮助提炼 SRD 和 EFA 要求以及审查设计。 作者还要感谢 AWS Nitro 芯片团队、EFA、SRD 和 LibFabric 团队构建了实现 SRD 和 EFA 的硬件和软件。
附录
一个TCP vs Infiniband vs SRD 协议的比较,以便更好理解。
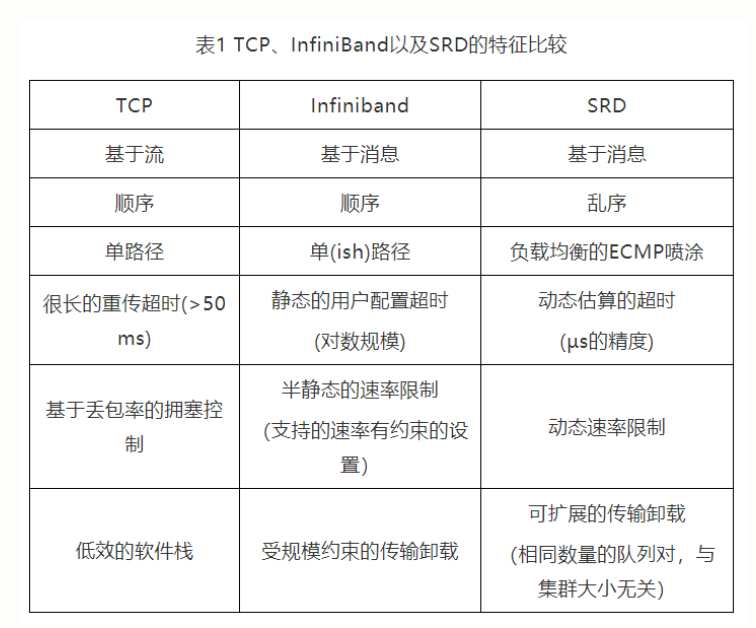
另外一些SRD相关的参考资料:
SRD 协议IEEE论文:https://ieeexplore.ieee.org/document/9167399
探秘AWS SRD技术:https://www.modb.pro/db/193519
EFA协议-SRD document: https://github.com/amzn/amzn-rivers/blob/master/kernel/linux/efa/SRD.txt
Amazon EFA: https://www.openfabrics.org/wp-content/uploads/2019-workshop-presentations/205_RRaja.pdf